 |
      |
Backups to Amazon's AWS Glacier Programming Project
| |
This is medium skill java/wscript programming project. You should have written your own programs using the
internet (i.e. Google) as a crutch and be able to integrate 'found code scraps' into a working programs without
having to ask for help. The Amazon interface is very well written and their examples work with a little
care in setting up the build/execute environment. There are times when I've been stumped for a few frustrating minutes
with an unhelpful java error message. A beginner might be stumped for a few frustrating days with the same error.
I'll give the same advice I gave on the "Setting up a Web Server in Your Basement". Your most valuable skill
will be knowing how to find obscure things with Google. People who post questions/solutions tend to be either
newbies who are struggling with how to ask a proper question or experts who assume you have an complete
understand of the topic and offer very brief and jargon laden responses. You may have to read a post,
spend an hour reading other posts, then return to the original post before you understand what is being said.
The Best Part: Amazon Glacier is Cheap for Backups
The cost is $0.01/Gigabyte/month. File deletes and reports are free. Uploads cost $0.05/1000 requests but you
can keep these costs low with a careful choice of program parameters (later). You can select where the data is
held so if you live on one coast then store your backups way off site on the other coast. Sooty lives in the
Vancouver, BC earthquake zone so having the offsite storage in Virginia is perfect.
In a perfect backup environment you never need to recover something. Backups are like an insurance policy...you
never want to submit a claim. Sooty stores two copies of six 4GB 'path' backups (C:\Pathx\...) and six 4GB
monthly incremental backups (more on this later). Uploading takes about 500 requests per month ($0.03) and the
72GB costs $0.72/month. That makes the all-in cost $9.00/year to provide backup coverage for roughly 25Gb of
"important" stuff.
If you do lose something the cost is $0.12/GB for downloads. I use 4GB archives so recovering a
deleted/lost file would cost 50 cents.
The Bad News: Amazon Glacier is Slow
There is a reason Amazon called it "Glacier". There are enforced throttles on requests that make the
service impractical for many applications. Uploading data (December 2012) runs about 100Kbytes/second. Within
a backup fragment it is 250 Kb/sec but there are hesitations between fragments that degrade the overall rate. A 4GB
file takes 10 hours to upload. Getting an inventory report on what you have in your 'vault' takes exactly
4 hours and it doesn't show changes (adds/deletes) that happened in the 4 hours prior to the request. Deletion
requests take 4 hours to process. Download requests take 4 hours to start then download at 100Kb/sec.
For a backup application most of the delays are manageable. You take a local image of your backup source, encrypt it
(more later on why) and upload it in the background. You automate the whole thing and you don't care how long it
takes. If you accidentally delete your Minecraft save and really, really want to play it tonight then recover it from
your local backup image. If your house burns down and ghosts your computer then the extra couple of hours to
recover your digital world is unimportant.
Part 1: Setting up Your Glacier Account
The first task is to create your Amazon Web Services (AWS) account aws.amazon.com.
Take the "My Account/Console" link at the top right of the page and follow the process. They will want your credit card
to create the account.
Once you have an account you will be offered a large number of cloud based services including virtual computers (EC2) and
highly data storage (S3) and database services (RDS). If you are a business Amazon could be a cost effective way to host
your data center (if you know how to manage the SLA).
Right now I'm assuming you are a small business or an individual that just wants cheap offsite backups. On the left
hand side there is "Getting started guide" if you're interested in the other services.
Select "Glacier...Archive Storage in the Cloud" and you are presented with a "Amazon Glacier Vaults" form and a lot of
whitespace. Select "Create Vault" and assign your "Vault Name" (I chose "Backups"). The name now appears in the form. Click
on the name and a form with "Details" appears. For now you just need an Vault to get started.
Under your account name (top right) select "Security Credentials" and copy your "Access Key ID" and your "Secret Access Key"
into a file somewhere. You will need these for your "AwsCredentials.properties" file. All your programs need a properly
populated properties file to allow access to your vault.
Part 2: Deciding on Your Development/Execution Environment
Now that you have a vault you can put things in it. This is where you have to decide on a build environment.
Amazon offers sample code for both Eclipse and non-IDE environments. Eclipse is very good about catching typos
and habits learned from other programming languages. I have a lot of the latter after years of programming in fortran,
cobol, apl, mumps, pascal, vb, c, c++, dcl, vbs, perl, and others. The problem with Eclipse is that as an IDE and you
will have to copy code to an execution environment to automate it. The programs are so small and modular that developing
in the execution environment with a good language sensitive editor (like TextPad) is effective choice.
The remainder of this page will assume you only have the execution environment and you will put all the code, libraries and
tools in that directory. The advantage is there is only one "here" and the code will look "here" for modules, reports
and logs will be created "here" and you can use wscript batch files to temporarily point to "here" for PATH and CLASSPATH
objects. Without the need for explicit pointers to external directory paths you can make copies of the execution
environment by just copying the contents of the directory to another directory. The disadvantage is that the directory
is cluttered with dozens of files. You wouldn't do this in a bigger project because it could be thousands of files
and a little clutter would turn into a huge management problem. For this project putting everything in one
"project directory" appropriate.
Part 3: Getting Libraries and Tools

August 2017 Update
During 2017 individual part uploads started to fail with:
Status Code: 403, AWS Service: AmazonGlacier, AWS Request ID: [...],
AWS Error Code: InvalidSignatureException, AWS Error Message:
The value passed in as x-amz-content-sha256 does not match the computed payload hash.
Computed digest: [...] expected hash: [..]
The part retry would return a success status
...but after the upload finished AWS would not provide an Archive ID
...instead it returned the error:
Status Code: 400, AWS Service: AmazonGlacier,
AWS Request ID: [...],
AWS Error Code: InvalidParameterValueException, AWS Error Message:
The total size of uploaded parts [...] does not equal the specified archive size [...]
By July 2017 these part upload failures were occurring every 1 Gbytes. A 2GB archive (my Monthly backup files)
would succeed most times but a 5 GB archive (my directory path backups) would always fail.
It appears over the period from 2014 to 2017 AWS had changed enough so the original JAR libraries were
now unreliable. Updating the JARs fixed the problem.
I have kept the Java 1.6.22 compiler because there are
serious complaints about Java 1.7 (bloat, complexity, performance, security ... the Window 8 complaints). I haven't seen
any glowing recommendations for Java 8 (most people like Windows 10) and I am testing my backups on Java 8.1.44 (they work).
Java 9 (out Fall 2017) is picking up the (important) new features and security from 1.7 through 1.8 and may be the magic
bullet for the complainers. I would never trust my automated backups to a x.0 version ... I'll wait for 1.9.1.
The instructions below show the updated libraries.
Things to put in your one and only project directory:
- Documentation: Get the "Amazon Glacier Developer Guide" from
here. This is where all the code examples live.
Leave the HTML pages up all the time while you're working. If you want to read before you code download
the 207 page PDF for your tablet or download the Kindle version.
- Software Development Kit (SDK): Get the current version (aws-java-sdk-1.11.172) from
here. It holds libraries (JARs), documentation,
and code samples all the AWS services...it's big enough to get lost in. We just need a few of the JARs to support our
code.
From the aws-java-sdk-1.11.172.zip extract the following to your project directory:
- aws-java-sdk-1.11.172.jar
and the required support JARs (suggest downloading from the Maven Repository)
- commons-codec-1.3.jar
- commons-logging-1.1.1.jar
- httpclient-4.5.3.jar
- httpcore-4.4.6.jar
- jackson-core-asl-1.9.13.jar
- jackson-mapper-asl-9.13.jar
- jackson-core-2.9.0.jar;
- jackson-databind-2.9.0.jar;
- jackson-annotations-2.9.0.jar;
- joda-time-2.9.9.jar
- AwsCredentials.properties - using an editor create this file and put in the following two lines:
secretKey=YOUR_SECRET_KEY
accessKey=YOUR_ACCESS_KEY
...where YOUR_SECRET_KEY and YOUR_ACCESS_KEY are the "Security Credentials" from Part 1
- Java - if you do not have the java compiler you need to install it. Get the current version from
here. Follow the installation instructions and remember where the javac compiler
was installed. Mine was put here "C:\Program Files\Java\jdk1.6.0_22\bin". This is the only external PATH link you will need.
If you can't figure out the path look for javac.exe in your "Program Files" and use that path.
Part 4: Uploading your First File
We will now build the program that uploads files to your vault. The program is only 37 lines including whitespace to make it
readable. All the work is done in the AWS libraries and all you have to do is stuff the interface with a few parameters and
you're done.
- ArchiveUploadHighLevel.java cut and paste from
here. Edit
the code to add in the "vaultName" and "archiveToUpload" (some dummy file) you want to upload.
- Build.bat (August 2017 version) - in an editor create a wscript batch file to compile and execute the uploader program. The file
contains the following lines:
rem Original (2014) JARs
rem --------------------
rem set CLASSPATH=%CLASSPATH%;C:\Backups-ToAmazon\5.LargeUploads\aws-java-sdk-1.3.17.jar;
rem set CLASSPATH=%CLASSPATH%;C:\Backups-ToAmazon\5.LargeUploads\commons-codec-1.3.jar
rem set CLASSPATH=%CLASSPATH%;C:\Backups-ToAmazon\5.LargeUploads\commons-logging-1.1.1.jar;
rem set CLASSPATH=%CLASSPATH%;C:\Backups-ToAmazon\5.LargeUploads\httpclient-4.2.1.jar;
rem set CLASSPATH=%CLASSPATH%;C:\Backups-ToAmazon\5.LargeUploads\httpcore-4.2.1.jar;
rem set CLASSPATH=%CLASSPATH%;C:\Backups-ToAmazon\5.LargeUploads\jackson-core-asl-1.8.7.jar;
rem set CLASSPATH=%CLASSPATH%;C:\Backups-ToAmazon\5.LargeUploads\jackson-mapper-asl-1.8.7.jar;
rem
rem Updated Replacements for Originals
rem ----------------------------------
set CLASSPATH=%CLASSPATH%;aws-java-sdk-1.11.172.jar;
set CLASSPATH=%CLASSPATH%;commons-codec-1.3.jar;
set CLASSPATH=%CLASSPATH%;commons-logging-1.1.1.jar;
set CLASSPATH=%CLASSPATH%;httpclient-4.5.3.jar;
set CLASSPATH=%CLASSPATH%;httpcore-4.4.6.jar;
set CLASSPATH=%CLASSPATH%;jackson-core-asl-1.9.13.jar;
set CLASSPATH=%CLASSPATH%;jackson-mapper-asl-1.9.13.jar;
rem
rem Added to Resolve "class not found" failures in New JARs
rem -------------------------------------------------------
set CLASSPATH=%CLASSPATH%;jackson-core-2.9.0.jar;
set CLASSPATH=%CLASSPATH%;jackson-databind-2.9.0.jar;
set CLASSPATH=%CLASSPATH%;jackson-annotations-2.9.0.jar;
set CLASSPATH=%CLASSPATH%;joda-time-2.9.9.jar
echo %CLASSPATH%
javac ArchiveUploadHighLevel.java
java ArchiveUploadHighLevel
If the program executes without error you have just uploaded your first file into your AWS Glacier Vault. For a small
file (a few Mbytes) the program should finish in seconds but the file will not show up in your vault for the AWS
enforced delay period of 4 hours. Take a break and when you come back we will build the program that reports on the
vault contents.
Part 5: Getting a Report on the Vault Contents
It was so easy to upload a file but getting a report is very complex (216 lines). Luckily the program is already
written for us and all we have to do is change a few things, compile and run.
Create a file called AmazonGlacierDownloadInventoryWithSQSPolling.java and paste in the contents from
here.
Ignore all the explanation at the top of the page and copy from the complete program at the bottom. Make the 5 changes
to the variable flagged by ***. The vaultName you know. I called the fileName "Inventory.log". The default
region is "us-east-1" unless you changed it. The two strange variable are just temporary so you can name them whatever
you want (I think) I used snsTopicName = "Backups_SNS_Inventory" and sqsQueueName = "Backups_Q_Inventory" which seems
to work fine.
Now replace "ArchiveUploadHighLevel" with "AmazonGlacierDownloadInventoryWithSQSPolling" in the Build.bat and you should
run without errors.
Note: this program hangs with an AWS enforced wait. It will hang for 4 hours then complete with a non-empty Inventory.log.
The inventory is returned in one long string which makes it extremely hard to read. If you put carriage returns in to make
sense of the report you get something like this:
{"VaultARN":
"arn:aws:glacier:us-east-1:715976268880:vaults/Backups",
"InventoryDate":"2012-08-23T07:54:37Z",
"ArchiveList":
[
{"ArchiveId":
"G4i-hhAP6YkWVgjil5qzlHNHlv2DwKRbSRVB1ne
I6Mnpac5RkQ0Ctg1g3UmACpjSbIB01N3yyk1IPe
5p0aek_PiMHvJHckDSAPuQyHqvp0uh3y8Dv3buE
KRNnVPp10spERxUvyNiLw",
"ArchiveDescription":
"my archive Tue Aug 21 23:05:08 PDT 2012",
"CreationDate":"2012-08-22T06:05:11Z",
"Size":49018880,
"SHA256TreeHash":"aa7a9b3bb228e7b0a0c17e61b87a39f6773c49d972f5195135893602c0761d87"
}
]
}
I'll leave it to you to parse this out and create a report that makes sense to you.
I parse the interesting bits out and put it into a MySQL database. I use the database to control aging of the backups. For example
(see below) I save 6 monthlies. My automated delete programs parse the database and if there are more than 5 monthlies it selects the
oldest and deletes that. I also use the database for restores so all I have to do is ask my restore program to retrieve an archive
by name. In both cases the programs deal with fetching that ugly 138 byte archive ID.
Part 6: Deleting a File from the Vault
This is a much simpler program (36 lines). There are no enforced delays so the request completes in seconds. The only way you
know that the request worked is to wait 4 hours and run an inventory report.
Create a file called ArchiveDelete.java and paste in the contents from
here.
You need to change the vaultName and insert the 138 character archiveId for the file you want to delete.
As an aside: In my automated procedures I parse the Inventory.log and load the five key pieces of data into a MySQL
database. When I upload a file I put the file name (BackupName) into the front of the ArchiveDrecription. When I
parse the report I extract the BackupName and the CreationDate and use that as the primary key. So the MySQL table
is defined by:
"CREATE TABLE Archives ( Primary Key (BackupName,CreationDate), BackupName varchar(40), ArchiveID varchar(138), ArchiveDescription varchar(80), CreationDate varchar(40), Size varchar(20), SHA256TreeHash varchar(64))";
When I want to delete a backup I select records based on the BackupName I want to delete:
rs = SQLstatement.executeQuery("SELECT * FROM Archives WHERE BackupName LIKE '" +DeleteBackupName+ " ' ORDER BY CreationDate;" );
...then I can take the archiveId from the 1st record I selected. Retention is just counting the number of records returned. If
I get 2 then I delete the oldest (i.e. the 1st record). If I only get 1 record then I don't delete any files. For Monthly
backups I keep 6 backups so if I count 6 or more in from the rs.next then I request AWS delete the oldest.
Part 7: Recovering a File from the Vault [updated July 2014]
*** Be extremely careful with this - it could cost you $1000s ***"
A warning on retrieval costs:
The PEAK download speed of all retrievals made in a month are added to get the "Peak-Retrieval-Bytes-Delta".
This is not something that is easy for you to calculate. During testing I downloaded four files (1Gb, 3Gb, 3Gb, 4Gb in 2 days)
and my bill for the month was $8.65 = $0.010 per GB for 865 GB peak (WTF???). Not a big amount
but if I had an automated job that downloaded 10Gb/day the monthly cost would be closer to $500.
If you are using this as a backup utility do NOT try to recover everything in the same month (after disk failure, fire, theft)...and
certainly do not use Glacier as a place to temporarily store all your photos, music and movies. Restores should be extremely rare and
small. If you follow the recommendations on this page (4GB archives and less than one retrieval per month) your costs should be less than $1.
From AWS documentation:
Glacier is designed with the expectation that retrievals are infrequent and unusual,
and data will be stored for extended periods of time. You can retrieve up to 5% of your
average monthly storage (pro-rated daily) for free each month.
...so if your largest archive is 4Gb and you keep 80Gb in storage (about 30 archives - this is my profile) you can download one archive
for free each month...which is a very good deal...just don't trigger the penalty clause.
There is as simple version (the High Level API - 36 lines) that only works for small files. It fails if there is
a momentary hiccup in the network link. Probably reliable for files less than 100Mb...not for 4Gb backups. (There
is a not so funny story about an emergency when I discovered the program I tested and trusted wouldn't restore my backup
- hence this 2014 update).
Create a file called ArchiveDownloadLowLevelWithRange.java (the last and most complex of the code samples) and paste
in the contents from here.
You'll need to find a bunch more libraries to get it to compile and depends on the newer 1.8.4 AWS SDK.
- aws-java-sdk-1.8.4.jar from \lib
- com.fasterxml.jackson.core.jar from \third-party
- com.fasterxml.jackson.databind.jar from \third-party
- com.fasterxml.jackson.annotations.jar from \third-party
- joda-time-2.0.jar from \third-party
There are a number of parameters that need setting. You need tell the program where your archive is stored: the vaultName,
the 138 character archiveId you got from your upload (or inventory), the region, and the file name for the restored archive.
You can leave the sns-topic and sqs-queue names suggested by the sample code.
The default 4Mb chunk size is a little small (too many transactions - see costing below). For a backup system restores should
be rare and a 4Mb chunk size will be more reliable. If you really need that backup waiting six hours only to have the thing fail
is a very bad outcome. Better to accept the higher transaction cost for a more reliable "works first time" restore.
This code sample wants to fetch security (AwsCredentials.properties) from C:\Users\username\.aws\credentials\ yet all the
other samples want to get it from the "run" directory. I suspect someone thinks the \Users path is more secure because it is
normally locked down on a Windows system. Having it in the "run" directory means you have copies in every test directory and
you might forget where all of the copies are.
I think putting the credentials in \Users is false security. If your system is hacked all files in all directories are available
to the hacker. More important who knows what security is being provided by Amazon? As a USA company Amazon is legally required
to give access to your archives to agencies like the NSA without informing you.
Proper security is to encrypt your archives and never have the encryption key anywhere on your computers. If you do that you
don't care if someone can hack your PC and download your files...what they have downloaded is useless without the encryption key.
So I copied the "credentials" code from the upload sample so my ArchiveDownloadLowLevelWithRange looks into the "run" directory
for AwsCredentials.properties.
Comment out the \Users code:
// ProfileCredentialsProvider credentials = new ProfileCredentialsProvider();
...and paste in the "run directory" version:
AWSCredentials credentials = new PropertiesCredentials(
AWSrestore.class.getResourceAsStream("AwsCredentials.properties"));
Note: This program hangs for 4 hours (AWS enforced) then begins the download after that. From what I can tell the
download rate is throttled at 400Kbytes/second (4 times the upload rate) so after the wait a 4Gb archive will
take another 3 hours...so you'll get your restored file in 7 hours.
One last thing. I use MySQL to store my (archive,achiveID,backupdate,decription) so all I have to do is tell my
restore job to fetch an archive by name and approximate date and it gets all it needs from the database. The sample
code has a AWS "policy" variable called "Statement" which collides with "java.sql.Statement". I won't go into it here but
you will need to "fully qualify" both so AWS gets along with SQL. If you are a java programmer you'll understand.
If not there's not enough room on this already busy webpage to explain it (sorry).
Part 8: TAR Backups
August 2017: I have switched to 7-Zip backups using a command line like:
7z a Monthly.zip "C:\Backups\Daily.zip" "C:\Backups\Thunderbird.zip" "C:\Backups\C_Full_Directory.zip"
...the strategy below for either TAR or 7-Zip or any archiving tool you like.
We now can upload, inventory, delete and download files from the AWS Vault so we are ready to put something useful into
the cloud.
I segment my backups so they are always less than 4 Gbytes and can fit on a DVD. As anyone who does backups I don't trust
them so I have three different media for my backups. I create my 4GB backup images and copy those to another computer on
my network.
Every month I burn the backup images to DVDs and throw them in my chest freezer. In the case of a fire or earthquake your
chest freezer has a better chance of surviving then you do. I now also upload them to an AWS server in Virginia. It's
like having a belt and suspenders sealed up with duct tape.
I use GNU Tar for Windows get it here. This
is a very simple implementation of Tar but you don't need much any archiving utility will do.
Add tar.exe, libiconv-2.dll, and libintl-2.dll to your AWS project directory.
If all you want to do is backup an entire path then:
tar --verbose --create --file=Pathx.tar "C:\Pathx\."
If you want to append a second path onto that tar:
tar --verbose --append --file=Pathx.tar "C:\Pathy\."
If you have many paths you can put them in a text file like ManyPaths.files:
C:\Path1\0
C:\Path2\0
C:\Path3\OnlyThese\0
C:\Path4\0
Then use that to drive the backup:
tar --verbose --create --file=ManyPaths.tar --files-from=ManyPaths.files
For incremental backups:
set mmm="dec"
set yyyy="2102"
set from=1 %mmm% %yyyy%
tar --verbose --create --newer="%from%" --file=Incremental.tar "C:\Path\."
Part 9: Encryption
I've encrypted all my archives with AES256. There is no guarantee of security in the cloud. I am absolutely certain Amazon
would never willingly make my archives public but they must operate under the rules of many governments and many
legal/policing entities inside those governments. Amazon may be forced to provide access to my archive without
notifying me. The encryption means no one will be able to view the contents of my archives unless I am legally
forced to provide my AES256 key.
Each of AWS archives has its own unique (rotating) key. If I am forced to release that key it cannot be used to
unlock any other parts of my digital life.
In the USA any data left on a server more than 180 days is considered abandoned. This comes from a time when disks were
so small that no one had room to store more than 180 days of emails and BBS logs. By law the search of abandoned files does
not require a warrant. Watch the four part presentation watch DEFCON 18: "The Law of Laptop Search and
Seizure" get it here.
or at least watch the cloud stuff in Part 3 (starting at 4:00 minutes).
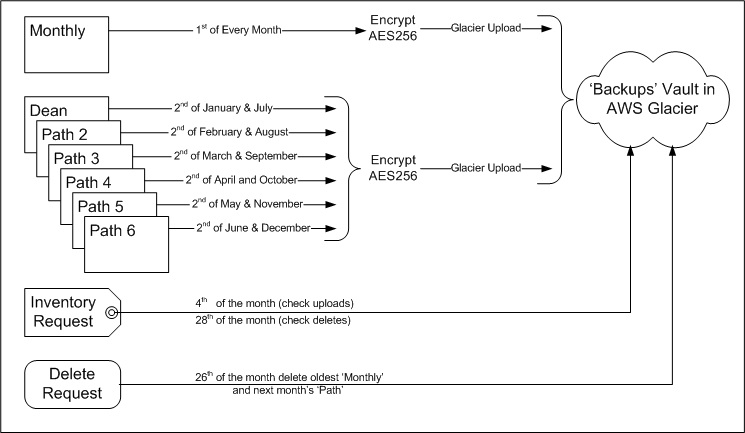
Part 10: Backup Schedule
The schedule of backups uploads a Monthly backup one the 1st of the month and one Path backup on the 2nd of the month
to the AWS Glacier vault. The Monthly includes a complete copy of the all Thunderbird emails and incremental
backups of all files from all Paths changed in the last month. These backups are about 4GB each and take about
10 hours to complete (100Kb/sec AWS rate limited) but only need 200 CPU seconds.
On the 4th of the month an AWS inventory report is request. These take 4 hours to run and do not report on any
archive changes 4 hours prior to the request. This appears to be an AWS attempt to limit churn.
On the 26th of the month the oldest Monthly (6 archives retention) and the oldest Path backup
(2 archives retention) are deleted from the vaults.
On the 28th another AWS inventory reports is requested to verify the deletes worked.
There are currently 6 Paths. For example the path called Dean is a TAR of C:\Dean\... and
contains an eclectic mix of subdirectories including investing, recipes, and the complete copy of the
sooty.ca website. The schedule upload the Dean Path in January and July (and deletes it in December and June).
In summary the backup schedule is:
1st : email and incrementals into Monthly. Encrypt and upload.
2nd : one of the 6 Paths (Dean on Jan and July, Path2 on Feb and Aug...). Encrypt and upload.
4th : Request AWS inventory to verify successful uploads.
26th : Delete oldest Monthly (keep 5) and oldest of this months Path (keep 1).
28th : Request AWS inventory to verify successful deletes.
Part 11: Costs and Uploading in Parts
The simple upload from Part 4 is not supposed to be used for large files. The proper method is "Uploading in Part" and
the ArchiveMPU program can be found
here.
The program is a little complex (120 lines) but simple to build and test. An uploaded file is broken into fragments and
each fragment is an upload request. The size of the fragment is left to the programmer. If there is a network failure then
small fragments can be retied with little impact on the upload data rate. Small fragments require more requests and
Amazon charges for each request so we want to keep the fragments as large as possible to minimize that cost.
The default "partSize" is set to 1 Mbyte which means a 4GB file requires 4000 requests. This fragment size is clearly too
small but what should the number be?
There is an absolute maximum of 10,000 requests for a single upload. At 1MB we could upload 9.7GB in 10,000 requests
but my archives are only 4GB so this is not a limit I have to worry about. In my application I'm going to be increasing the
fragment size making this limit even less important.
There are three major cost components to the cost of our backup system and we want to minimize each. Storage
is $0.01 per Gbyte. Requests are $0.05/1000. Downloads are $0.12 per Gbyte.
We don't plan to do any downloads (perhaps once a year to test that my backup process will yield a perfect recovery) so
that cost is zero. See the warning in Section 7 on the large costs of frequent downloads.
I keep two copies of 6 paths and 6 monthly's so my 72GB costs 12x$0.72 = $8.64/year
I upload 2x4GB of data per month and the fragment size affects the number of requests. If use the default
1 Mb then I need 8000 requests or $.40/month which is half of my storage costs so it's worth looking at.
Requests are $0.05/1000 requests rounded up to the penny:
1 to 199 requests = 1 penny
200 to 399 requests = 2 pennies
400 to 599 requests = 3 pennies
600 to 799 requests = 4 pennies
800 to 999 requests = 5 pennies
1000 to 1199 requests = 6 pennies
A 4Mb fragment size for 8GB of uploads takes 1000 requests or $0.10
To reduce the "request cost" to 0.01/month we need a 10 times larger fragment size (40MB).
Fragments must be a power of two so the next nearest is 64Mb and 8GB/64Mb = 128 requests = $0.01
At 100Kb/second upload speed a 4Mb fragment takes 40 seconds (about 0 to 2 failures/upload).
At 100Kb/second upload speed a 64Mb fragment takes 640 seconds or 10 minutes.
64MB = 128 requests = $0.01 & 640 sec (10.6 minutes)
32Mb = 256 requests = $0.02 & 320 sec ( 5.3 minutes)
16Mb = 512 requests = $0.03 & 160 sec ( 2.7 minutes) ← this rate verified in actual uploads
8Mb = 1024 requests = $0.06 & 80 sec
4MB = 2048 requests = $0.11 & 40 sec
It looks like the "sweet spot" is 16MB.
For $0.03/month I could upload 9.5GB/month.
The 5.3 minute fragment upload time would risk some increased fragment failures (need to check this).
The best parameter looks like 16MB or a partSize = 16777216 in ArchiveMPU. This should give the best
balance of cost and reliability. It also means the 10,000 request limit would restrict uploaded file
size to 156GB if we reused the program for another application.
A map of the backup schedule:
|