 |
      |
Backups to Google Drive Programming Project
| |
This is a programming project (educational toy) for someone with advanced Java experience (and a tolerance for alpha release libraries).
The project consists of a program that spawns 7Zip to break a large archive (mine are 5GB) into volumes (I use 100MB)
uploading these using Google Drive REST SDK V2.
This project is based on the V2 support libraries but if you are looking for an adventure you can convert it to run under
the V3 SDK.
You can follow the progress of the upload using the Google Drive web interface
and use it to download archives to recover lost or damaged files. Along with GDriveUpload I include Java programs
[GDriveReport, GDriveDelete, GDriveDownload] that
do these functions. In an automated backup these can all be hidden behind UI so the user does not have to know the
cloud storage is provided by Google.
This webpage starts with a lecture on Backup Basics you can skip if you are only looking for example code to implement your preferred strategy.
Backup Strategy
A good backup strategy has separate archives with related content. Copying all of C:\... will certainly be safe
but it will include files you have no interest in saving: heaps of temporary files that applications create and rarely clean up, crash dumps,
temporary downloads and caches, and that dreadful porn video your buddy sent you.
Segment your life using the file system. Put the pet pictures in one archive and separate from your financial records and legal documents.
This means individual archives are smaller and restoring lost files is simpler and quicker. For a service like Drive separating
your archives by function allows you to order them by importance. Backup the critical high turnover files frequently and only back up those
that fit within the 15GB Google Drive 'free' limit.
Separate the more important stuff from the leaser. Note that "user friendly" operating systems like Windows and OS X discourage this.
In your home you don't tuck your passport into the same shelf with old magazines. Your consumer OS will try to put both in the same Documents folder.
In each archive you should have the contents ordered by importance. An archive should be a groups of folders and use the folder name
as a flag. Put really important things in a "0-folder" put junk in a "z-folder". If the backup aborts part way through the important stuff will get saved. If you run out
of room discard the stuff at the bottom of the list and make the archive smaller.
Only back up things that cannot be replaced. Your kids pictures should be the top of the list it's own archive that should be at the top
of that list of all archives. Put your brother-in-law's kids pictures in a different archive because a) they aren't your kids and b)
if you lose them you can always get another copy from your brother-in-law (assuming he's backed up).
Only back up important stuff and you will never need more than the capacity you get for free (unless you are a developer/hardware hacker like me).
Currently that's 15GB. Over time your life will get more data intensive but you can be certain over time the size of free storage will also grow.
If today you really do need more than 15GB then Google will sell you 100GB for $2.79/month (three times the cost of Amazon AWS) or
1000GB for $9.99/month (the same price as AWS).
Segmented Backups Advantages and Uglies
Google Drive appears to have a catastrophic fault about every 10GB of upload traffic. If you have large archives you get to a point
where uploads will have a 100% failure rate. For example a 3D movie at 1080p compresses down to about 14GB.
My archives are a mixture of pictures and
programs and spreadsheets and tax records and knitting patterns and technical books and ripped music CDs...the data warehouse of a digital family.
I keep this warehouse in folders that when zipped fit on a DVD (4.7GB). When my stuff in C:\Dean was to big to fit on a DVD it got split into
C:\Dean and C:\DeanArchive. I do incremental saves every day and full folders backups once a month. The 15GB gives me two full paths, a month of
incrementals, and a smaller path (DVD/2).
The failure rate of Drive based on uploads of whole archives (this project without split volumes) means I get at least one failure every month.
Recovering from a failure (delete the broken upload then prepare and upload its replacement) takes as long as just uploading the
archives manually...so more trouble than it is worth.
I'm not interested in paying for more than 15GB until I can get an automated backup that runs trouble free for at least a year.
I only started split backups in July 2017 and they appear to be reliable.
(My AWS implementation has been relatively trouble free since August 2012).
The solution is to break large archives into smaller segments and code the upload program to be super sensitive about any kind of exception.
If the program thinks there's a problem: redo the segment. On download (recovery) if there are duplicate segments take the latest one. A 5GB
archive breaks into 50 segments of 100MB. A failure every 10GB means one retransmit every 100 segments which puts a 1% overhead using the
strategy. The archiving process can be fully automated with a predictable run time and a nearly 100% reliability.
Now for the ugly part. Instead of one 5GB file you have 50 segments. Using the Drive webtool what you see is a mess. You don't see
Dean.aes (recall all my cloud storage is AES encrypted with a rotating key): you see Dean.7z.001, Dean.z7.002, ..., Dean.7z.050. And
that's mixed in with DeanArchive.7z.001 to DeanArchive.7z.050 and Incremental.7z.001 to Incremental.7z.009.
The solution is to put all the segments into a Drive "folder". At the "Backups" root level you only see folders: Dean, DeanArchive, Incremental
... all the ugliness is buried in the next level. When you want to delete and replace the archive just delete the folder (thankfully Drive deletes all
the contained files). When you report what
archives are stored in Drive exclude any entry that looks like a 7Zip split volume.
As a comparison AWS uploads in 16MB segments and my upload log occasionally reports segment exceptions. The AWS library code makes it easy
to retry on an exception. When I do an AWS directory I only see files (not segments) but that may be a clever function of the AWS library routines.
Getting Access to a Google Drive
Getting your free 15GB Google Drive is easy. Sign up for gmail (doesn't everybody have gmail?), go to
http://drive.google.com, and log in with your gmail ID and password. You will be in the Drive webtool:

The next part is a little more complicated. You must register as a developer and get the credentials to access your drive from a Java program.
Go to http://console.developers.google.com/

In the windows that says "Search all 100+ APIs" enter "Drive":
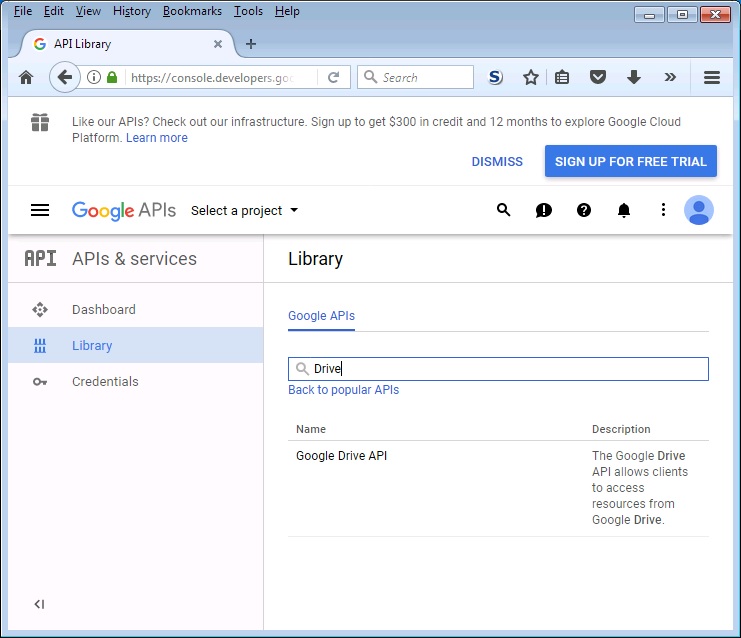
Click on "Google Drive API" and accept the "terms" for using the API.

Created a project: Backup
...Your project ID will be backup-999000
Click on "Select a project" (top left) select "Backup" and a "Select" popup will appear ... click "Open"
...click "OAuth consent screen" tab
...enter a "Product name shown to users" Backups Test and "Save:
Click "Credentials" tab a "Credentials" popup will ask you to "Create credentials"
...choose "OAuth client ID" and it asks for "Application type">br>
...choose "Other" and enter the name "Drive API Quickstart" and "Create"
You will now get your security credentials:
Here is your client ID:
999999999999-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.apps.googleusercontent.com
Here is your clilent secret
yyyyyyyyyyyyyyyyyyyyyyyy
Click "V" (right hand edge) and Download JSON ... it saves:
client_secret_999999999999-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.apps.googleusercontent.com.json
Copy this file to the working directory and rename it client_secret.json
The client_secret.json file is used by your Java program to access your Drive. Without it you will
get an authoriztion failure. It uniquely identifies both your Drive and is your password to
the Drive contents.
Development Environment (IDE)
Not needed. If you have a favorite load my sample java code and the IDE. The problem is that when an IDE encounters an unresolved
class it goes out and finds it for you. The Google Drive libraries are a mess and you may or may not get a compatible library. The safest
route is to take the JARs from the zip file provided by this webpage and manually reference them in your IDE. Support sites
are full of "Won't Compile" or "Won't Run" that require (often complex) fixes to the IDE environment.
My suggestion is get my simple java programs running without an IDE first. Once you have a working example move from "working" to
"working in an IDE" then you can start to use the very powerful tools the IDE provides to build a "commercial" version.
Google Drive Reporting: Program GDriveReport.java
The first things to do is get a directory of your Drive contents. If this code works it becomes the basis for
GDriveUpload, GDriveDelete, and GDriveDownload.
Create an empty directory. UnZip GDriveReport.zip into it.
Replace the client_secret.json with the one you got from the developer registration.
Install the latest Java 8 SDK jdk-8u144-windows-i586.exe.
If you already have a favorite version of the Java SDK installed you will have to edit the GDriveReport.cmd and change the line:
set PATH=%PATH%;C:\Program Files\Java\jdk1.8.0_114\bin
to reflect the version you are using.
Review of GDriveReport.java. There are only 126 lines log most of them are declarations to reference the library classes and print statements to format the Drive
metadata into a report.
The key parts are:
Credential authorize() - converts your client_secret.json into a credentials (think usename/password)
drive = new Drive.Builder - creates a handle to access your Drive
FileList l = drive.files().list().setMaxResults(200).execute() - fetch Drive metadata from your cloud storage
Important: [import com.google.api.services.drive.model.File] has replaced the File services that you know and love from java.io.file.
When you see code that looks like standard Java file I/O do not be confused. The File classes from Google Drive only access file-like
structures in the cloud. They cannot be used to access local files.
The [File fileHandle = new File("test.txt")] you learned as a novice
programmer will not compile in the [public static void main] class. You can only access to local files by coding classes in a separate
Java source that avoids the Google libraries. Experienced Java developers will understand how this works and use the technique for
it strengths but someone who just wants to build a small backup package will get tripped up by the choices Google has made.
As a comparison: AWS libraries add cloud functions but do not replace any standard Java classes so they are novice friendly.
Run GDriveReport.cmd and you should see a report of My Drive. Use your browser webtool to create folders, upload files, delete files, ... and
run the report to see how those change what you can see from a Java program.
The sample GDriveReport.java reports on everything. It is left to you to modify the code to skip all the *.7z.999 files and just show your backup
directories.
Deleting Google Drive objects: Program GDriveDelete.java
The next program you need to understand is how to delete Drive objects (what?). This is only a little more complex then GDriveReport (170 lines)
and it uses the object handles that the report has fetched.
Preparation is simple:
Using the webtool at http://drive.google.com (you may have to log in) right-mouse-click on "My Drive"
(upper left) and create a folder (I used "Backups"). Right-mouse-click in the white space in the center of the screen and select "Upload files".
It will open a window to your PC's Desktop and you can navigate around to select a file to upload. Now you have a folder and a file to delete.
Edit GDriveDelete.cmd and change the line:
java GDriveDelete TestFile.txt Backups
to the file and folder you created.
Run GDriveDelete.cmd and the report it creates should tag the file you selected for destruction. Refresh the browser and the webtool should
show the file is missing.
Review of GDriveDelete.java shows it is nearly identical to GDriveReport except when it encouters a file and folder matching the hit list
it flags the file as "trash" then executes an "emptyTrash":
drive.files().trash(file.getId()).execute(); //flag file as trash
drive.files().emptyTrash().execute(); //empty all files in trash
Next create a folder called TestFolder in your Backups folder and populate it with a couple of test files. Edit GDriveDelete.cmd to flag the
sub-folder as the target:
java GDriveDelete TestFolder Backups
Running GDriveDelete.cmd will delete the folder and anything stored in that folder. There is no need to individually delete the files in the
sub-folder. We will need this fact later when we are managing our segmented files.
7-Zip for Splitting Archives into Volumes
7-Zip is a free open source tool for managing packed file formats. Here it is used to create
split volumes but it can unpack a large number of formats ZIP, TAR, BZIP2, RAR, and many more. I also use it to peak inside Java JARs, ePub books
and even EXEs to see what classes they use.
The command line used is:
7za a -v100m -mx0 Dean Dean.aes
7xa.exe must be in the same directory as GDriveUpload
a - means add to an archive ... in this case the archive is the split volumes
-v100m - means volume size is 100 Mb
-mx0 - means do not compress ... just copy (it's already compressed)
Dean - the file name for the output archive volumes
Dean.aes - the input archive to split
Since Dean.aes is 5GB the result will be 50 files named Dean.7z.001, Dean.z7.002, ... , Dean.7z.050
GDriveUpload deletes the volumes after the upload is complete to keep the local directory uncluttered.
Asynchronous Threads
When you start a 7-Zip thread to split volumes it returns immediately. You could monitor the thread and wait for it to end but
it may end without creating all the split volumes. It is safer to check that each volume has been created. Once 7-Zip has created all
the volumes it goes back to the root volume (Dean.7z.001) and updates its status. You must check this update is complete before uploading any
for the volumes to Drive. Since the Google SDK
replaced the "File" from java.io.file you need to put the 7-Zip and file checking in separate class like
SplitFile.java
Monitoring the Upload Volumes Parts
Google Drive uploads in parts that default to a size of 10MB. I break up my archives into 100MB volumes so each volume is uploaded as 10 parts.
If you want to monitor the parts upload you need a thread that is triggered after each part completes. When you declare an uploader:
MediaHttpUploader uploader = insert.getMediaHttpUploader();
you can define a class (FileUploadProgressListener.java) to monitor (and log) the upload progress:
uploader.setProgressListener(new FileUploadProgressListener());
Putting it all together (with some verbose logging) you have GDriveUpload.java
Logging for a Jobs Scanner
The logging is important because if you have caught all the obvious failure modes there maybe rare modes you miss. For example my AWS backups
fail about once every 100GB (6 months) and I use the logs to capture these rare errors. Some errors can be captured and recovered during the upload.
Those go into version updates.
Others modes are not recoverable but they trigger an alarm from my Jobs Scanner. The scanner parses the logs from all the automated jobs I run
(runs once a day). It parses the verbose logs looking for something "unusual" and brings up a Javax window (like one I use for my
MarketWired dividend notice scanner).
Automated Backups
Put parameterized programs in a single batch job (Backups.cmd) as:
- set arcfile="Dean"
- backup C:\%ArcFile% to %ArcFile%.zip then ssl into an %ArcFile%.aes
- java GDriveDelete %ArcFile% Backups
- java GDriveUpload %ArcFile%.aes Backups
- java GDriveReport
Put this into the Windows scheduler to run at 1:00 AM on the 1st of each month and you have an automatic backup process. For a
more complete explanation of an automated backup systems see the AWSbackups webpage.
|