 |
      |
Backups to Google Drive using Drive Sync Programming Project
This attempt is unreliable for large (2GB+) backups ... this webpage is an archive only.
See Google Drive Backups for a better approach.
| |
This is beginners java/wscript programming project. The project consists of a script using 7-Zip to create a ZIP
archive of disk path, a script the encrypts the archive in AES256 using openssl and copies the result to a working
directory, and a Java program that manages Google Drive so it reliably uploads the archive to the cloud.
Backup Strategy
A good backup strategy has separate archives with related content. Copying all of C:\... will certainly be safe
but it will include files you have no interest in saving: heaps of temporary files that applications create and rarely clean up, crash dumps,
temporary downloads and caches, and that dreadful porn video your buddy sent you.
Segment your life using the file system. Put the pet pictures in one archive and separate from your financial records and legal documents.
This means individual archives are smaller and restoring lost files is simpler and quicker. For a service like Drive separating
your archives by function allows you to order them by importance. Backup the critical high turnover files frequently and only back up those
that fit within the 15GB Google Drive 'free' limit.
Separate the more important stuff from the leaser. Note that "user friendly" operating systems like Windows and OS X discourage this.
In your home you don't tuck your passport into the same shelf with old magazines. Your consumer OS will try to put both in the same Documents folder.
In each archive you should have the contents ordered by importance. An archive should be a groups of folders and use the folder name
as a flag. Put really important things in a "0-folder" put junk in a "z-folder". If the backup aborts part way through the important stuff will get saved. If you run out
of room discard the stuff at the bottom of the list and make the archive smaller.
Only back up things that cannot be replaced. Your kids pictures should be the top of the list it's own archive that should be at the top
of that list of all archives. Put your brother-in-law's kids pictures in a different archive because a) they aren't your kids and b)
if you lose them you can always get another copy from your brother-in-law (assuming he's backed up).
Only back up important stuff and you will never need more than the capacity you get for free (unless you are a developer/hardware hacker like me).
Currently that's 15GB. Over time your life will get more data intensive but you can be certain over time the size of free storage will also grow.
If today you really do need more than 15GB then Google will sell you 100GB for $1.99/month (about twice the cost of Amazon AWS) or
1000GB for $9.99/month (the same price as AWS).
Google Drive Reliability Problems
If you just dump files into Google Drive you will run into many frustrating problems. The message boards are
full of posts by people who complain that Drive is unusable. The truth is Google should have this perfectly
reliable by now but problems persist. A poorly swung hammer will often bend the nail...a nail gun is always true. The
current version of Drive is more hammer than nail gun.
Sync process crashes and aborts are the most annoying. If you give Drive too many files to sync at the same time
the process will report "lost connection" or just "failed". It does allow you to manually retry but the only option
is a simultaneous retry of all the failed uploads so of course it crashes with the same error. The only
way to get the sync process working is to shut down Drive, delete all the failed uploads, restart Drive and feed
it fewer files to sync (probably one at a time).
Sometimes Drive doesn't even tell you it failed to sync a file. You spend all day working on something and move it
into the Drive directory. When you check you find your updated file gone and replaced by the day-old version. This can be
a heart renching loss becaues you haven't just lost a few pages of work. You have lost a creative state that you may never recover.
Until Drive is relaible always keep a second backup copy of important work separate from your Drive archive.
If you don't have something for Drive to do every day it falls into a deep coma and refuses to sync anything. This
and the unreported aborts are the major case of stale files in the Drive. Google suggests you constantly check that
sync is working and do a shutdown/restart to wake it up. If you've been adding files slowly over many days and discover
Drive is asleep waking will force it to try to sync it all of them at once and you'll get the multi-file crash problem.
If you manual delete a file in Drive (and sync is working) it will notice and update the cloud storage to reflect the
change...but it does not delete the copy in the cloud. It moves it to "Trash" and these deleted files count against your
15GB limit.
If you have a mumble.dat on the local PC Drive and you delete it then replace it with an updated mumble.dat
Drive will do the right thing and you will get an updated mumble.dat in the cloud. If you do that many times all
the deleted versions in "Trash" will use up your 15GB quota and the sync will crash/abort. It may or may not tell
you. So you have to manually force "Trash" to 'really' delete all its copies. Occasionally not all copies are visible and
you have to shutdown/restart Drive to see all the files then 'delete and empty' to get rid of the phantom files
eating up your quota.
Making Google Drive Reliable for Backups
My Amazon AWS backups have been working for several years at 100% reliable. Google Drive is my plan B if
Amazon screws with AWS and breaks my primary backup system...I need Drive to be 100% reliable.
Based on other's experience: Drive cannot handle more than one thing at a time, deleting a file in
the local (PC) Drive will eventually require manual (i.e. non-automated) action to clear the Trash, and
best way to ensure sync will work is to ask a freshly started sync process to do it.
The automated solution is:
- Select the next archive to be updated
- Kill googledrivesync.exe to shut down Drive
- Delete the sync_log.log where Drive tracks it's activity
- Delete the old archive file from the Drive directory (Drive is not watching)
- Move in the replacement (updated) archive in the Drive directory
- Start googledrivesync.exe to rewaken Drive (creates an empty sync_log.log)
- Drive will (reliably) discover the swapped file
- Monitor the sync_log to verify Drive has completely uploaded the new archive
- Goto Step 1 until all the archives have been updated
This process ensures Drive is only doing one thing at a time. It also ensures Drive never sees a 'delete'.
When it wakes up it will be 'surprised' to find one of the files it owns has changed and (usually) uploads the
replacement. In fact if the replacement archive is identical to the cloud version it will do the right
thing and not upload the duplicate content.
What follows is a step-by-step explanation of the environment setup and coding details to implement the automated
solution.
If I find my sync_log monitoring version is not 100% reliable I will put up a version using the Google REST api. This will
look a lot like the code I used for my AWS Backups. Using REST will change the project
from a simple Java project to an advanced Java project.
Part 1: Setting up Your Google Drive Account
If you have a gmail account you are 90% done because the 15GB cloud storage comes with gmail. If not go
here to create one. Your gmail address and password are
your access to Google Drive.
From the PC that will hold the local Drive files install
the Drive software. I have many computers on my LAN and I use an old Window XP computer (MediaX) to do Drive testing.
Several of my computers use Drive for backups and they copy their archives to MediaX. I have Drive installed and the
Drive web page running at all times on MediaX so I can remote console to monitor Drive's behaviour.
I use gmail from my primary system and I have apps on my phone (like my fitness tracker and my hiking tracker)
that share Drive space but these are configured to not have copies of the backup archives. I don't want a
bunch of duplicate 15GB copies of backups scattered across my systems. Later I'll show you how to block
Google Drive from storing these duplicate archives.
The installation will place your browser into the cloud view of your Drive. Click on 'New' and create a folder called "Backups".
This will create a subfolder called "Backups" in the cloud and it will also create a subfolder on your PC called
\Backups that you will use for archives. Don't screw this up...the programs rely on this subfolder being present.
Part 2: Deciding on Your Development/Execution Environment
There is only a single Java program and it runs on the PC that holds the Drive archives (where you installed Drive).
This is where you have to decide on a build environment for that program. If you are an experienced Java programmer
you will normally do development in an "Interactive Development Environment" or IDE (probably Eclipse). If you are an
IDE user you know what you like in your environment...so do that. The rest of this section uses a simple
wscript/batch/cmd without an IDE.
Install Java "Software Development Kit" (SDK) for the Drive PC. Mine is an old 32 bit XP so I used (local copy)
jdk-7u3-windows-i586.exe (version 1.7.03). If your Drive PC is a more
common 64 bit you'll need (local copy) jdk-7u3-windows-x64.exe. The current version
is 1.8.101 (July 19, 2016) but any 1.7 version has support for the libraries I used. If you want the latest version get it from
Oracle. You can get old versions
from Oracle but you have to create an Oracle account for 1.7 or older versions.
Part 3: Google_Sync
Create your build directory (mine was C:\BackupsGoogle) and copy in Google_Sync.java and
make a build file that includes:
rem Point PATH to the java 1.7_03 compiler
rem --------------------------------------
set PATH=%PATH%;C:\Program Files\Java\jdk1.7.0_03\bin
javac Google_Sync.java
java Google_Sync
Google_Sync implements the "automated solution" described above. It looks in a "source" directory (C:\BackupsPending) for any file. These files are assumed to be
updated versions of files currently in the "destination" Drive directory. It kills googledrivesync.exe,
deletes sync_log.log, delete any file in the Drive directory that has the same name as the file in the "source",
moves the source file to the Drive directory and restarts googledrivesync.exe. The program parses sync_log.log
to monitor Drive activity while it uploads the file.
You may need to change some of the parameters that are hard coded into the top of the java file. It is hard coded so I can
form it into a single exe in the future. If you need use the code in multiple/changing environments then pass
the parameters in as arguments.
Google_Sync.log holds a sample of my August 2016 "production run" syncing file files (150Mb to 4GB).
The code does olog.flush() after every status update so you can open the log and find out what is happening while
the program is running.
In case you were curious AWSrestore.zip (the only non-AES encrypted file in the Drive archives) is the complete kit of my
java code, AWS and other libraries, and script files needed to turn any computer into a device to restore my 120 GB of
Amazon AWS archives. Yes, that means my AWS recovery kit is stored on Google Drive and to
complete the "belt and suspenders" my Google Drive code is backed up to AWS.
2015 August Update: The code was rewritten. Originally I used a timed approach
that was based on a fixed 75Kb/second net transfer rate (Google enforced throttle). The actual transfer
rate varied between 38Kb/second and 80Kb/second. It might have been my ISP or Google or some blockage between the
two. With the transfer rate no longer reliable a new Google_sync.java parsed sync_log.log for events that verified
the progress of the archive sync.
2016 April Update: Google has changed the behaviour of the sync_log.log file. The format of this file is 'undocumented' so Google
is perfectly within their rights to make such changes. Using 23 Mb "parts" to track progress is no longer reliable. My updated
Google_Sync.java has added a new section of parsing code that tracks 9 Mb "packets" and now accurately predicts upload
progress based on the new sync_log.log format.
2016 July Update: Drive appears to have partially fixed the "lost connection" problem. If you check my new Google_Sync.log you will find
it is pretty good at estimating the finish time for a sync. The first estimate uses 90 Kb/sec but it checks the actual network
performance at [10% done, 20% done, ..., 90% done] and recalculates the finish time. I am using 3 GB archives and testing has shown about
25% of the uploads fail and network traffic drops to zero. After some time (unpredictable delay) Drive discovers something is
wrong and restarts the sync (probably from the begining). This will show up in the log as a loop at "90% done" estimating how much
time it take to do another 10%. The good news is that Drive will eventually resync the troubled archive.
Part 4: Encrypting and Copying Archives
I've encrypted all my archives with AES256. There is no guarantee of security in the cloud. I am absolutely certain
Google would never willingly make my archives public but they must operate under the rules of many governments and many
legal/policing entities inside those governments. Google may be forced to provide access to my archive without
notifying me. The encryption means no one will be able to view the contents of my archives unless I am legally
forced to provide my AES256 key.
Each of the AWS archives has its own unique (rotating) key. If I am forced to release that key it cannot be used to
unlock any other parts of my digital life.
In the USA any data left on a server more than 180 days is considered abandoned. This comes from a time when disks were
so small that no one had room to store more than 180 days of emails and BBS logs. By law the search of abandoned files does
not require a warrant. Watch the four part presentation watch DEFCON 18: "The Law of Laptop Search and
Seizure" get it here.
or at least watch the cloud stuff in Part 3 (starting at 4:00 minutes).
I use (local copy) openssl-0.9.8h-1-bin.zip to encrypt the archives. You can
also get ssl from GnuWin.
I create the archive using 7-Zip:
7z a Network.zip "C:\Network Equipment Configurations\*.*" -r
...then encrypt the zip archive with:
C:\openssl\bin\openssl aes-128-cbc -salt -in Network.zip -out Network.aes -k NetworkRotatingKey
...and copy the encrypted file to MediaX computer for Google_Sync to find:
copy /y Network.aes \\MediaX\C\BackupsPending\*.*
Part 5: Network Data Rate
The estimated network data rate is set at the top of the java file. My uploads seem to peak at 85Kb/sec but they can
be much slower. Google may change this throttle at any time or your network link may affect the transfer rate.
There seems to be no way to increase the upload rate ("Don't limit" ~ 75Kb/sec on average). Download rate is as fast
as your ISP can go (mine is 25Mbit). If Google removes their throttle you may find your automated uploads sucking your internet
link dry. You may want to limit the upload and download links so backups get along with other uses/users.
From Windows Start run Google Drive. Click the little green-orange-blue symbol in the tray then click the three dots
(settings) then click "Preferences..." to bring up the panel below (click for larger) then click the "Advanced"
tab:
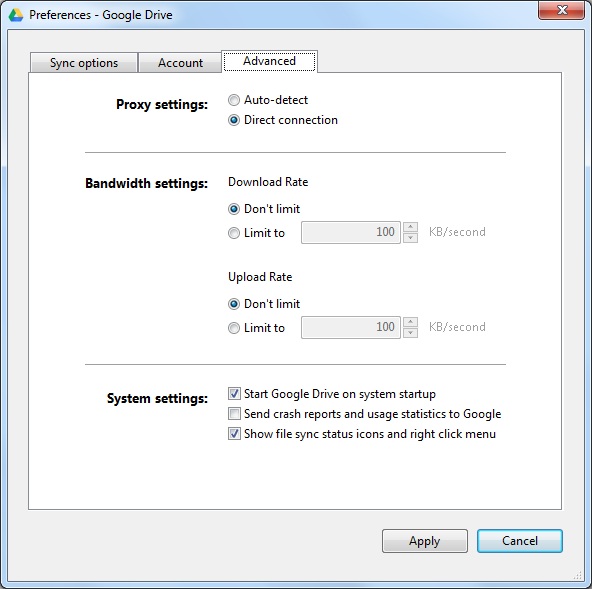
If Google switches to a real 'unlimited' upload rate a reasonable throttle on uploads would be the 100Kb/sec limit that AWS uses.
Since downloads are probably a manual restore "Don't Limit" is probably reasonable.
Part 6: O/S Specific Google Drive Location
You will need to change the "destination" depending on Windows version and user account. Note that
the Java path separator is "/" (not \) which must be escaped with a \ in the definition string (so \\).
On Windows XP (MediaX) (Administrator account) the Drive defaults to:
Drive: C:\Documents and Settings\Administrator\My Documents\Google Drive\Backups
Java:
static String destination = "C://Documents and Settings//Administrator//My Documents//Google Drive//Backups//";
sync_log:
C:\Documents and Settings\Administrator\Local Settings\Application Data\Google\Drive\user_default\sync_log.log
Java:
static String sync_log =
"C://Documents and Settings//Administrator//Local Settings//Application Data//Google//Drive//user_default//sync_log.log";
On Windows 7 and 10 (Administrator account) the Drive defaults to:
Drive: C:\Users\Administrator\Google Drive\Backups
Java: static String destination = "C://Users//Administrator//Google Drive//Backups//";
sync_log: C:\Users\Administrator\AppData\Local\Google\Drive\user_default\sync_log.log
Java:
static String sync_log = "C://Users//Administrator//AppData//Local//Google//Drive//user_default//sync_log.log";
Part 7: Limiting Duplicate Copies of Backup Archives
When you install Google Drive on another system it will create a copy of every file in every folder of the cloud
on your secondary PC. You need to exclude the \Backups path from the "Sync Options" on every secondary system.
From Start run Google Drive. Click the little green-orange-blue symbol in the tray then click the three dots
(settings) then click "Preferences..." to bring up the panel below (click for larger):
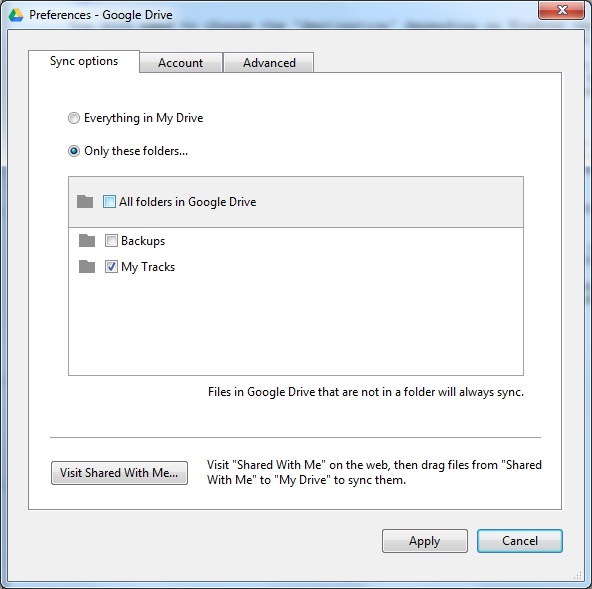
The default is "Everything in My Drive". Select "Only these folders..." and untick Backups.
"My Tracks" is a folder used by a hiking app on my phone. I let it be shared across all systems with
Google Drive installed.
|